股票配资公司平台 《经济学人》评DeepSeek:中国AI快赶上美国了,特朗普遭遇难题
发布日期:2025-03-15 00:35 点击次数:62
我们关注中国在生成式人工智能(AI)领域的进展。自 ChatGPT 声名大噪以来,美国在人工智能领域相对中国的领先优势,如今看起来比以往任何时候都小。中国的大型语言模型或许并非顶尖水平股票配资公司平台,但制造成本却低得多。这些模型的成功,再加上整个行业的变革,可能会彻底颠覆人工智能领域的经济格局。美国必须为中国人工智能紧追不舍的世界做好准备。

《经济学人》封面文章|中国AI正在追赶,给唐纳德·特朗普带来难题
Chinese AI is catching up, posing a dilemma for Donald Trump
如果说有一项技术能实现唐纳德·特朗普总统在就职演说中承诺的“国家成功的激动人心新时代”,那就是生成式人工智能。往小了说,人工智能将增加未来十年的生产力,推动经济增长。往大了说,它将推动人类经历一场堪比工业革命的变革。
特朗普在次日主持了“史上最大的人工智能基础设施项目”的启动仪式,这表明他意识到了人工智能的潜力。但世界其他国家也意识到了——尤其是中国。就在特朗普发表就职演说时,一家中国公司发布了最新的、令人印象深刻的大型语言模型DeepSeek。突然间,美国在人工智能领域相对于中国的领先优势,看起来比ChatGPT成名以来的任何时候都要小。
中国的追赶令人震惊,因为它曾经远远落后,也因为美国曾试图拖慢它的脚步。在保护壁垒之下,硅谷曾趾高气扬。中国研究人员如饥似渴地研读美国的人工智能论文,而美国人却很少关注中国的成果。然而,中国最近的进展正在颠覆该行业,让美国的政策制定者们感到尴尬。中国模型的成功,再加上整个行业的变化,可能会彻底改变人工智能领域的经济格局。美国必须为中国人工智能紧追不舍的局面做好准备。
中国的大型语言模型并非最顶尖的。但它们的制造成本要低得多。电商巨头阿里巴巴旗下的通义千问于11月推出,与美国的顶级模型相比,差距不到三个月。由一家投资公司分拆出来的深度求索,其模型按一项基准排名第七。显然,它是用2000块二流芯片训练出来的,而Meta的模型则用了1.6万块一流芯片,在某些排名中,深度求索(DeepSeek) 的模型还超过了Meta的模型。训练一个美国的大型语言模型成本高达数千万美元,而且还在上升。深度求索的所有者表示,其训练成本不到600万美元。
如果美国公司愿意,它们可以复制深度求索的技术,因为其模型是开源的。但廉价的训练会在模型设计不断发展的同时改变这个行业。特朗普就职当天,深度求索发布了“推理”模型,旨在与OpenAI的先进模型竞争。这些模型在回答问题前会进行自我“思考”。这种“思考”能得出更好的答案,但也会消耗更多电力。随着输出质量的提高,成本也会增加。
结果是,正如中国降低了构建模型的固定成本一样,查询模型的边际成本也在上升。如果这两种趋势继续下去,科技行业的经济格局将会逆转。在网络搜索和社交网络领域,复制像谷歌这样的巨头需要巨大的固定投资成本,并且要有承受巨额亏损的能力。但每次搜索的成本却微乎其微。这一点,再加上许多网络技术固有的网络效应,使得这些市场呈现赢家通吃的局面。
如果足够好的人工智能模型能够以相对较低的成本进行训练,那么模型将会大量涌现,尤其是因为许多国家都迫切希望拥有自己的模型。而且,每次查询的高成本也可能会促使更多为特定目的而构建的模型出现,这些模型能够以最少的查询提供高效、专业的答案。
中国取得突破的另一个后果是,美国面临着不对称竞争。现在很明显的是,中国将围绕诸如缺乏最佳芯片等障碍进行创新,无论是通过提高效率,还是通过增加数量来弥补高质量硬件的不足。中国国产芯片正在不断改进,包括华为设计的芯片。华为这家科技公司曾在一代人之前以价廉物美的方式使其电信设备得到广泛应用。
如果中国能紧跟前沿,它可能会率先实现向超级智能的飞跃。一旦发生这种情况,它可能获得的不仅仅是军事优势。在超级智能的情况下,赢家通吃的局面可能会再次出现。即使该行业保持目前的发展轨迹,中国人工智能在全球的广泛应用也可能会给中国带来巨大的政治影响力,这至少与TikTok一样令美国担忧。
特朗普应该怎么做?他宣布的基础设施项目是个不错的开端。美国必须清除建设数据中心的法律障碍。还应该确保外国工程师的招聘变得容易,并改革国防采购,以鼓励人工智能的快速应用。
一些人认为,他还应该废除芯片行业的出口禁令。拜登政府也承认,该禁令未能遏制中国的人工智能发展。但这并不意味着它毫无作用。在最坏的情况下,人工智能可能像核武器一样致命。美国永远不会向其对手提供制造核武器的部件,即使他们有其他途径获得这些部件。如果中国现在能重新轻易获得最好的芯片,中国的人工智能肯定会更强大。
更重要的是,要缩减拜登的“人工智能传播规则”草案,该草案将规定哪些国家能够获得美国的技术。其目的是迫使其他国家加入美国的人工智能生态系统,但科技行业认为,繁琐的规定反而会适得其反。随着中国的每一次进步,这种反对意见变得更加可信。如果美国认为其技术是印度或印度尼西亚等国的唯一选择,那它可能会高估自己的实力。一些技术专家承诺,下一项创新将再次让美国遥遥领先。也许吧。但认为美国的领先地位是理所当然的,这是很危险的。
《经济学人》封面文章|中国人工智能产业几乎已追上美国
China’s AI industry has almost caught up with America’s
而且,中国的人工智能产业更加开放,效率也更高

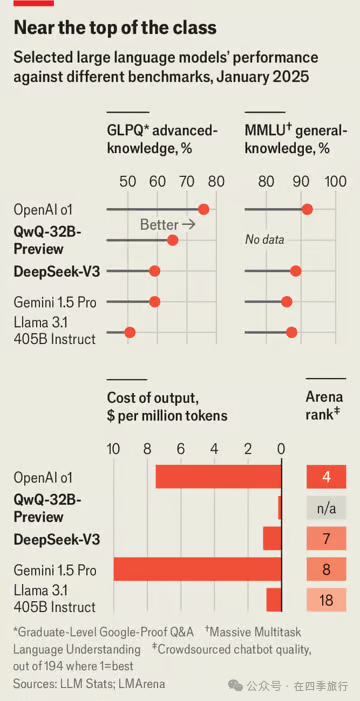
全球首个“推理模型”——一种先进的人工智能形式,于9月由美国公司OpenAI发布。这款名为o1的模型运用“思维链”来解答科学和数学领域的难题。它将问题拆解成各个步骤,在幕后测试各种解决方法,然后才向用户给出结论。o1的问世引发了一场竞相模仿该方法的竞赛。12月,谷歌推出了名为“Gemini Flash Thinking”的推理模型。几天后,OpenAI又推出了o1的升级版o3。
图表:《经济学人》
但实际上,拥有雄厚资源的谷歌并非第一家效仿OpenAI的公司。在o1发布不到三个月后,中国电商巨头阿里巴巴就发布了其聊天机器人通义千问的新版本QwQ,具备同样的“推理”能力。另一家中国公司深度求索(DeepSeek),在此一周前就发布了一款推理模型R1的 “预览版”。尽管美国政府试图遏制中国的人工智能产业发展,但两家中国公司已将美国同行的技术领先优势缩短至几周。
中国公司不仅在推理模型方面处于前沿:12月,深度求索发布了一款新的大型语言模型(LLM),这是一种能够分析和生成文本的人工智能。v3模型大小近700GB,拥有6850亿个参数,这些参数相互结合形成了模型的神经网络。这使得它比此前任何可供免费下载的模型都要庞大。Meta(Facebook的母公司)于7月发布的旗舰大型语言模型Llama 3.1仅有4050亿个参数。
深度求索的大型语言模型不仅比许多西方同类模型更庞大,质量也更优,仅逊色于谷歌和OpenAI的专有模型。人工智能编码平台Aider的创始人保罗·高蒂尔,让深度求索的新模型通过了他的编码基准测试,结果发现,除了o1本身,该模型超越了所有竞争对手。由众包完成的聊天机器人排名平台Lmsys将其排在第七位,高于其他任何开源模型,也是谷歌和OpenAI之外的公司所发布模型中的最高排名(见图表)。
巨龙登场
如今,中国人工智能在质量上已与美国竞争对手不相上下,以至于OpenAI的首席执行官山姆·奥特曼觉得有必要解释两者差距为何如此之小。中国的深度求索(DeepSeek)发布v3后不久,奥特曼就烦躁地在推特上发文称:“复制已知可行的东西(相对)容易。但在不知道是否可行的情况下,去做一些全新、冒险且困难的事,极其困难。”
中国人工智能产业起初看似二流。在大约一年的时间里,阿里巴巴的成果并不值得兴奋:它只是基于Meta开源的Llama大型语言模型开发出的一个相当普通的 “分支”。但在2024年期间,随着阿里巴巴不断发布通义千问的迭代版本,其质量开始提升。西方人工智能实验室Anthropic的杰克·克拉克,在一年前阿里巴巴发布了一款既能分析文本又能分析图像的通义千问版本时表示:“这些模型似乎能与西方顶尖实验室开发的非常强大的模型相竞争。”
中国的其他互联网巨头,包括腾讯和华为,也都在打造自己的模型。但深度求索(DeepSeek)的起源有所不同。阿里巴巴发布首个通义千问模型时,深度求索甚至还不存在。它源自一家成立于2015年的对冲基金High-Flyer(幻方),该基金利用人工智能在股票交易中获取优势。开展基础研究助力该幻方成为中国最大的量化基金之一。
但据幻方创始人梁文锋,其动机并非纯粹出于商业目的。他观察到,OpenAI的首批支持者并非追求回报,他们的动机是 “追寻使命”。2023年通义千问发布的同月,幻方宣布也将加入打造通用人工智能的竞赛,并将其人工智能研究部门分拆出来成立了深度求索。
和OpenAI之前一样,深度求索承诺为公共利益开发人工智能。梁文锋表示,公司将公开大部分训练成果,试图防止这项技术被少数个人或公司 “垄断”。与OpenAI不同,OpenAI因训练成本不断飙升而被迫寻求私人资金,而深度求索一直可以使用幻方庞大的计算能力储备。
深度求索庞大的大型语言模型不仅因其规模引人注目,还因其训练效率高而备受关注,即模型通过输入数据来推断其参数。剑桥大学的尼克·莱恩表示,这一成功并非源于单一的重大创新,而是一系列微小改进的结果。例如,训练过程经常使用舍入法简化计算,但在必要时保持数字精确。服务器集群经过重新配置,使单个芯片之间能够更高效地通信。在模型训练完成后,利用深度求索的推理系统R1的输出进行微调,学习如何以更低成本模拟其质量。
得益于这些及其他创新,生成v3的数十亿参数所需的芯片运行时间不到300万小时,估计成本不到600万美元,约为Llama 3.1计算能力和成本的十分之一。v3的训练仅需2000个芯片,而Llama 3.1使用了16000个。而且由于美国的制裁,v3使用的芯片甚至并非最强大的。西方公司在芯片使用上似乎愈发铺张:Meta计划建造一个使用35万个芯片的服务器集群。特斯拉前人工智能负责人安德烈·卡帕西表示,深度求索就像穿着高跟鞋倒着跳舞的金杰·罗杰斯,让 “用极少预算训练前沿模型这件事看起来轻而易举”。
不仅模型训练成本低廉,运行成本也更低。深度求索在多个芯片之间分配任务的效率比同行更高,并且在前一步骤完成之前就开始下一步骤。这使得芯片能够满负荷工作,几乎没有冗余。因此,2月,当深度求索开始允许其他公司基于v3创建服务时,其收费将不到Anthropic的大型语言模型Claude使用费用的十分之一。人工智能专家西蒙·威利森表示:“如果这些模型质量确实相当,那么这将是大型语言模型定价大战中一个戏剧性的新转折。”
深度求索对效率的追求并未就此止步。本周,在完整发布R1的同时,它还发布了一组更小、更便宜、速度更快的 “提炼” 变体模型,其性能几乎与更大的模型相当。这效仿了阿里巴巴和Meta的类似做法,再次证明它能够与该行业的巨头竞争。
巨龙之道
阿里巴巴和深度求索还以另一种方式挑战西方最先进的实验室。与OpenAI和谷歌不同,这两家中国实验室效仿Meta,以开源许可的方式提供其系统。如果你想下载一个通义千问人工智能,并在此基础上开发自己的程序,无需特别许可即可进行。这种开放性还体现在一种非凡的透明度上:这两家公司每当发布新模型时,都会发表论文,详细介绍用于提升模型性能的技术细节。
阿里巴巴发布QwQ时,成为全球首家以开放许可发布此类模型的公司,任何人都可以下载完整的20GB文件,在自己的系统上运行,或者拆解开来研究其工作原理。这与OpenAI的做法截然不同,OpenAI对o1的内部工作原理秘而不宣。
大致而言,这两种模型都采用了所谓的 “测试时计算”:与前几代大型语言模型不同,它们并非仅在模型训练期间集中使用计算能力,在回答查询时也会消耗更多算力(见商业板块)。这是心理学家丹尼尔·卡尼曼所称 “系统2” 思维的数字化版本:比快速本能的 “系统1” 思维更慢、更审慎、更具分析性。这种思维方式在数学和编程等领域已取得了不错的成果。
如果你被问到一个简单的事实性问题,比如说出法国的首都,你可能会脱口而出脑海中浮现的第一个词,而且很可能是正确的。典型的聊天机器人工作方式也大致相同:如果其语言统计表示给出了一个占压倒性优势的首选答案,它就会相应地完成句子。
但如果你被问到一个更复杂的问题,你往往会以更有条理的方式思考。当被要求说出法国人口第五多的城市时,你可能会先列出一长串法国大城市;然后尝试按人口数量进行排序,之后才给出答案。
o1及其模仿者的诀窍,是引导大型语言模型进行同样形式的结构化思考:系统不再是不假思索地说出脑海中最合理的答案,而是将问题拆解,逐步找到答案。
但o1将思考过程保留在内部,仅向用户展示其过程总结和最终结论。OpenAI为这种选择给出了一些理由。例如,有时模型会思考是否使用冒犯性词汇或披露危险信息,但随后会决定不这么做。如果其完整的推理过程被公开,那么敏感内容也会随之曝光。但模型的这种谨慎也使得其推理的精确机制对潜在模仿者保密。
阿里巴巴则没有这样的顾虑。让QwQ解决一道棘手的数学题,它会愉快地详细阐述每一步思路,有时在尝试各种解题方法时会 “自言自语” 数千字。“所以我需要找到20198 + 1的最小奇质因数。嗯,这个数看起来相当大,但我想我可以逐步分解它。” 模型开始这样表述,在生成2000字的分析后,正确得出答案是97。
位于葡萄牙的Poolside公司,是一家为程序员开发人工智能工具的公司,其联合创始人艾索·康德表示,阿里巴巴的开放性并非偶然。他指出,中国实验室与行业其他公司一样,都在争夺人才。“如果你是一名考虑出国的研究人员,西方实验室无法给予你的是什么?我们不能再开放我们的成果了。由于我们所处竞争的性质,我们把一切都锁得紧紧的。” 康德说,即使中国公司的工程师不是最先发现某项技术的人,他们也常常是最先发表成果的人。“如果你想看到任何秘密技术问世,那就关注中国的开源研究人员。他们会公开一切,而且做得非常出色。” 莱恩指出,v3发布时所附的论文列出了139位作者的姓名。这样的赞誉,可能比在美国实验室默默无闻地辛勤工作更具吸引力。
美国政府决心阻止先进技术流向中国,这也让在美国的华裔研究人员日子不太好过。问题不仅在于旨在对最新创新成果保密的新法律所带来的行政负担,还常常存在一种模糊的怀疑氛围。甚至在社交活动中,也会无端出现间谍指控。
中国实验室希望围绕自己的人工智能打造一个企业生态系统。这在商业上有一定价值,因为基于开源模型开展业务的公司,最终可能会被说服从模型开发者那里购买产品或服务。这也为中国带来战略优势,因为在与美国的人工智能竞争中,它能借此建立盟友。
驻上海的科技投资者弗朗西斯·杨指出,对于苹果和三星等急于在中国销售的设备中融入人工智能工具的公司来说,本土合作伙伴必不可少。甚至一些国外公司也有使用中国模型的特殊原因:通义千问特意被赋予了对乌尔都语和孟加拉语等 “资源稀缺” 语言的流畅运用能力,而美国模型主要使用英语数据进行训练。此外,中国模型运行成本极低,这也极具吸引力。
但美国人工智能仍具备中国竞争对手目前尚无法匹敌的能力。谷歌的一个研究项目,将用户的网络浏览器交给其Gemini聊天机器人,这使得人工智能 “代理” 与网络交互成为可能。Anthropic和OpenAI的聊天机器人不仅能帮你编写代码,还能为你运行代码。Claude将构建并托管整个应用程序。而且逐步推理并非解决复杂问题的唯一方法。问传统版本的ChatGPT上述数学问题,它会编写一个简单程序来找到答案。
据奥特曼称股票配资公司平台,更多创新正在酝酿中。预计他很快将宣布,OpenAI已经打造出 “博士级超级代理”,在一系列智力任务中具备与人类专家相当的能力。来自中国竞争对手的紧逼,或许会促使美国人工智能取得更大成就。
- 上一篇:正规期货配资平台有哪些 正式命名为N°8 DS旗舰产品内饰官图曝光
- 下一篇:没有了